[Python] Pandas DataFrame 간단한 사용법
Python에서 Pandas library를 통해 데이터 전처리가 널리 이용되면서 대표적 자료구조인 DataFrame 사용법을 아는 것이 중요해졌다. 따라서 이에 대해 간단하게 요약하고자 한다.
기본 구조
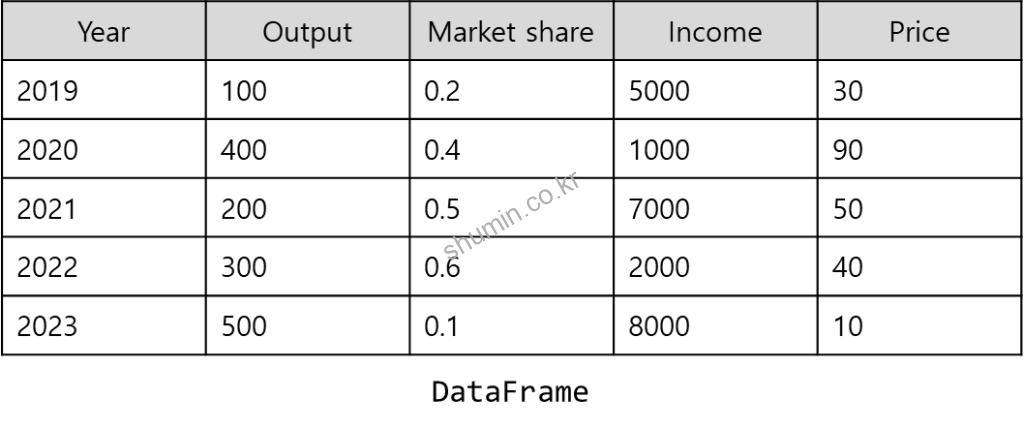
DataFrame은 기본적으로 행과 열로 구성되는 행렬이라 생각하면 쉽다. 위 그림을 Python code로 DataFrame instance를 만드는 방법은 다음과 같다.
import pandas as pd
raw_data = [
{"Year": 2019, "Output": 100, "Market share": 0.2, "Income": 5000, "Price": 30},
{"Year": 2020, "Output": 400, "Market share": 0.4, "Income": 1000, "Price": 90},
{"Year": 2021, "Output": 200, "Market share": 0.5, "Income": 7000, "Price": 50},
{"Year": 2022, "Output": 300, "Market share": 0.6, "Income": 2000, "Price": 40},
{"Year": 2023, "Output": 500, "Market share": 0.1, "Income": 8000, "Price": 10}
]
df = pd.DataFrame(raw_data)
df

참고로 Jupyter notebook을 사용하면 시각화를 잘 해주기 때문에 Pandas를 이해하는데 도움이 된다. Jupyter에선 DataFrame의 instance를 출력하면 행렬로 나타내준다.
Row Title
print(df.index.tolist())
| [0, 1, 2, 3, 4] |
DataFrame에선 row를 index라고 부르는데, 만약 index를 설정하지 않으면 default로 0부터 들어가게 되어 위 그림에서 보면 0부터 4까지 입력이 된 것을 볼 수 있다.
df.set_index("Year")

만약 index (row title)을 변경하고 싶을 때는 set_index() 함수를 통해 특정 column을 row title로 설정할 수 있다.
Column Title
print(df.columns.tolist())
DataFrame의 column title을 얻는 방법은 위 방법으로 가능하다.
Row Indexing
print(df[1:3])

만약 특정 row (행)만 얻고자 할 때는 위 코드처럼 []을 통해 접근 가능하다. 특징은 한 row만 가져오고 싶어도 slicing : 연산자를 사용해야 한다.
Column Indexing
df["Market share"]
| 0 0.2 1 0.4 2 0.5 3 0.6 4 0.1 Name: Market share, dtype: float64 |
만약 1개의 column만 접근할 때는 특정 column의 title을 적으면 된다. 그리고 출력되는 타입은 series다.
df[["Market share"]]

만약 출력 타입을 DataFrame으로 가져가고 싶은 경우엔 [[]]으로 대괄호를 2개를 사용하면 된다.
df[["Market share", "Price"]]

만약 특정 column만 가져오고 싶은 경우 column title들을 적어주면 된다.
print(df.columns[2:5]) df[df.columns[2:5]]

Slicing 연산자로 이어진 column들을 가져오는 방법은 위와 같이 사용이 가능하다.
Delete Row and Column
만약 행과 열을 제거하고자 할 때는 drop() 을 사용해 행과 열을 제거할 수 있다.
df.drop(3, axis=0) # df.drop(3, axis=0, inplace=True)

df.drop("Income", axis=1)
# df.drop(3, axis=0, inplace=True)

drop()의 첫 번째 인자로는 labels 또는 index를 넣어주면 된다.axis=0인 경우 행을 제거한다.axis=1인 경우 열을 제거한다.- 만약 원본
DataFrame의 값을 변경하고자 할 때는inplace=True인자를 전달하면 된다.
Column Name Update
df.columns.str.replace(' ', '_')

만약 column name을 변경하고자 할 때는 DataFrame.columns 를 수정하면 된다.
Row Name Update
for index in df.index:
if str(index).isdigit():
df.rename(index={index: f"{index}-year"}, inplace=True)
df

만약 set_index()를 통해 index를 설정 후, row name (index)을 업데이트하고자 하면, rename()을 통해 index의 각각을 변경 할 수 있다.
df.rename(index={index: }는 모든 index들에 대해 적용하기 위해 {index: }가 사용되었다.
추가로, index title을 바꾸는 방법은 아주 쉽게 df.index.name = "Next Name"으로 변경이 가능하다.
Index Reset
df.reset_index(inplace=True) df
그리고 만약 index를 다시 원래의 숫자 (0, 1, 2, …)로 돌리고 싶으면 reset_index(inplace=True)를 통해 원복 가능하다.
Row and Column Indexing
iloc vs. loc
Row와 column을 동시에 indexing하기 위해선 iloc과 loc에 대해서 알아야 한다. iloc는 숫자를 통해 indexing하는 방식이며, 반면 loc는 행/열의 이름을 통해 access를 하기 때문에 여러개의 이름을 list 등으로 감싸서 전달 가능하다.
또한 iloc는 0부터 직전 요소까지 읽어오며, loc는 마지막 요소를 포함해 읽어온다.
참고로 iloc과 loc은 DataFrame의 property이기 때문에 []로 사용한다.
iloc 사용법
df.iloc[2:5]

Column 5는 제외되는 것을 명심해야 한다.
df.iloc[:, 2:4]

만약 특정 행이 아닌 열을 읽기 위해선, 첫 번째 행에 해당하는 인자는 :로 입력하고 뒤에 행에 대한 정보를 정수로 전달한다.
df.iloc[2:5, 2:4]

loc 사용법
df.set_index("Year", inplace=True)
df.loc[["2020-year", "2022-year"]]

df.loc[["2020-year", "2022-year"], "Market share":"Price"]

loc을 사용하게 되면 문자열로 행 또는 열을 지정했음에도 slicing : 기능이 가능하다.
Boolean Indexing
- 특정 조건에 따라 DataFrame에서 원하는 부분을 선택하는 기능이다.
- DataFrame의 열에 대한 조건을 지정하여 해당 조건을 만족하는 행을 선택하게 된다.
- 조건은 각각 boolean 자료형으로 구성되며, 조건을 만족하는 여부에 대한
Series형태로 반환된다.
df["Price"] >= 50
| Year 2019-year False 2020-year True 2021-year True 2022-year False 2023-year False Name: Price, dtype: bool |
df[df["Price"] >= 50]

만약 Price가 50 이상인 년도에 대한 결과를 보려면 위와 같이 작성하면 된다.
df[df["Price"] >= 50][["Market share", "Income"]]

만약 Price가 50 이상인 년도에 대해 Market share와 Income만 보고 싶다면 위와 같이 작성하면 된다.