[Algorithm] Generic Hash
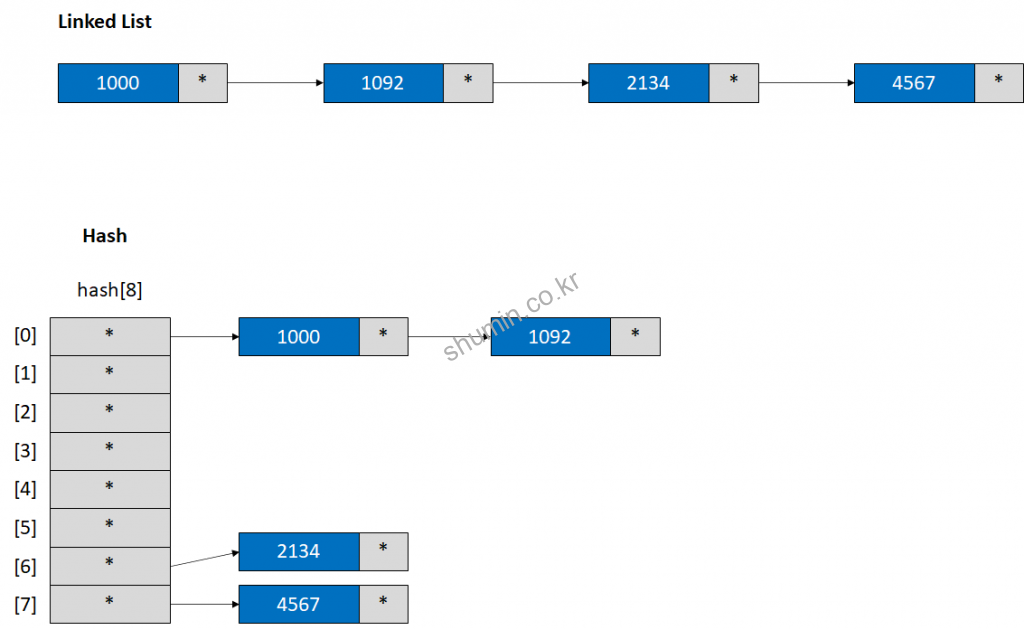
Linked List 구조에서 특정 데이터를 찾고자 할 때, head가 가리키는 노드부터 찾을텐데 만약 데이터가 가장 마지막 노드에 있다면 시간복잡도 기준으로 O(N)이 된다.
Hash에선 bucket이라는 구조가 사용되는데, hash function을 거쳐 나온 값을 통해서 bucket을 indexing하게 되며, 각 노드가 head가 되어 linked list 구조를 가진다. 이렇게 bucket을 통해서 분산배치를 할 경우 시간복잡도는 O(N / Bucket Size)가 되는데, 이는 반드시 hash function을 통해 분산배치를 시켜야지 이득이 된다.
Description
hlist_add_head
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
void hlist_add_head(struct hlist_node *n, struct hlist_head *h) {
struct hlist_node *first = h->first;
n->next = first;
if(first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
새로운 노드가 들어오게 되면 우선 기존 hash bucket의 next pointer (first)가 존재하는지 확인하고, 만약 존재한다고 하면 이미 존재하는 bucket의 다음 pointer인 first의 이전 노드를 가리키는 포인터 (pprev)를 새롭게 들어오는 노드의 next pointer의 주소를 넣어주게 된다. 이 때 이중 포인터가 사용되게 된다.
display
우리가 구현한 구조를 화면으로 출력해주는 코드를 작성해보면 다음과 같이 될 수 있다.
void display(struct hlist_head *head) {
system("clear");
for(int i=0; i<HASH_MAX; i++) {
struct hlist_node *temp;
PERSON *p;
printf("[%d]", i);
for(temp = head[i].first; temp; temp=temp->next) {
p = container_of(temp, PERSON, hash);
printf("<->[%d]", p->id);
}
printf("\n");
}
getchar();
}
우선 bucket의 entry에 들어있는 포인터 값을 받아서 포인터에 연결된 linked list를 출력해주는 방식으로 동작한다.
system(“clear”)를 통해 매번 화면을 지워서 깔끔하게 표시해주고, temp라는 iterator를 통해 다음 노드로 넘어가게 된다.
여기서 container_of 매크로를 통해 PERSON 구조체의 주소값을 받아서 우리가 구하고자 하는 id 값을 접근한다.
Hash Function
Hash function이 얼마나 균일하게 bucket index를 나누는지에 따라서 성능이 달라진다. Modulo 함수는 하위 bit에 따라서 index가 달라져서 무조건 좋은 함수라고 보기 어렵다.
실제 kernel에서 hash function은 pid_hashfn 이라는 이름을 가진다. 실제 내부 함수는 아래와 같다.
#define pid_hashfn(nr, ns) \
hash_long((unsigned long)nr + (unsigned long)ns, pidhash_shift)
함수 인자 중 pidhash_shift는 2의 지수승을 나타낸다. 만약 bucket size가 8이라고 하면 3을 넣어주면 된다. 그리고 앞 인자 nr, ns의 합이 실제 우리가 hash function에 주는 입력값이다. 실제 내부에 호출되는 함수를 따라가보면 아래와 같은코드가 나온다.
#define GOLDEN_RATIO_PRIME_32 0x9E370001UL
unsigned hash_long(unsigned val, unsigned bits) {
unsigned int hash = val * GOLDEN_RATIO_PRIME_32;
return hash >> (32 - bits);
}
어떠한 값에 매우 큰 소수 (GOLDEN_RATIO_PRIME_32)를 곱한 다음 입력된 값의 수만큼 최상위 bit 수를 구하는 것이다. 예를 들어, bucket size가 8인 구조에 1000 이라는 값을 val에 넣는다고 하면 다음과 같다. 해당 값을 16진수로 변경하고 큰 소수를 곱한 뒤 상위 3 bits을 index에 사용한다.
1000 (Decimal) -> 3E8 (Hexa)
-> 0x3E8 * 0x9E370001UL = 0x26A06D803E8
-> 0x26A06D803E8 = 1001101010 00000110 11011000 00000011 11101000
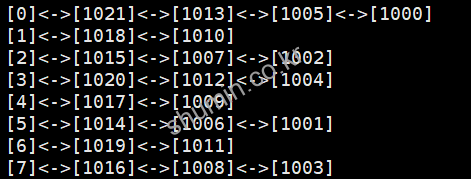
이렇게 최종 수정된 hash function까지 적용하고 난 뒤 코드와 결과는 다음과 같다.
Final Code and Result
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member));})
#define GOLDEN_RATIO_PRIME_32 0x9E370001UL
#define pid_hashfn(nr, ns) \
hash_long((unsigned long)nr + (unsigned long)ns, pidhash_shift)
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
void hlist_add_head(struct hlist_node *n, struct hlist_head *h) {
struct hlist_node *first = h->first;
n->next = first;
if(first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
unsigned int hash_32(unsigned int val, unsigned int bits) {
unsigned int hash = val * GOLDEN_RATIO_PRIME_32;
return hash >> (32-bits);
}
//-------------- User Program --------------
#define HASH_MAX 8
#define PERSON_NUM 30
typedef struct {
int id;
struct hlist_node hash;
} PERSON;
int log_2(int x) {
return (int)(log(x) / log(2));
}
unsigned hash_long(unsigned val, unsigned bits) {
unsigned int hash = val * GOLDEN_RATIO_PRIME_32;
return hash >> (32 - bits);
}
int hash_func(int i) {
return hash_long(i, log_2(HASH_MAX));
// return i % HASH_MAX;
}
void display(struct hlist_head *head) {
system("clear");
for(int i=0; i<HASH_MAX; i++) {
struct hlist_node *temp;
PERSON *p;
printf("[%d]", i);
for(temp = head[i].first; temp; temp=temp->next) {
p = container_of(temp, PERSON, hash);
printf("<->[%d]", p->id);
}
printf("\n");
}
getchar();
}
int main()
{
struct hlist_head heads[HASH_MAX] = {0,};
int hash_num, id;
PERSON p[PERSON_NUM] = {0,};
display(heads);
for (int i=0; i<PERSON_NUM; i++) {
id = 1000+i;
p[i].id = id;
hash_num = hash_func(id);
hlist_add_head(&p[i].hash, &heads[hash_num]);
display(heads);
}
}